
Viele moderne Applikationen bieten neben einer ansprechenden UI auch den Wechsel zwischen verschiedenen Themes an. Für gewöhnlich wird zumindest zwischen Hell und Dunkel unterschieden. Gleiches gilt für das Betriebssystem selbst – Windows und macOS bieten dem User jeweils die Wahl zwischen Hell und Dunkel. Auch Avalonia bietet mit dem FluentTheme seit Version 0.10 einen sehr einfachen Weg an, zwischen hellen und dunklen Modus zu unterscheiden. Typischerweise wird das FluentTheme in der App.xaml angegeben und bekommt als Mode entweder „Light“ oder „Dark“. In diesem Artikel wollen wir uns damit beschäftigen, wie diese Einstellung zur Laufzeit der Applikation verändert werden kann. Weiterhin schauen wir uns an, wie man unter Windows den aktuell konfigurierten Theme herausbekommt und sogar auf Änderung des aktuellen Theme reagieren kann.
Blog
Avalonia Applikationen übersetzen
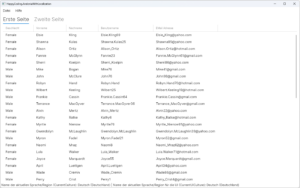
In den letzten Monaten habe ich vermehrt Artikel über das Cross-Platform Framework Avalonia geschrieben. Für mich persönlich hat sich das Framework mittlerweile zum Standard für Desktop-Applikationen entwickelt. Es kann fast alles, was man braucht und läuft auf allen gängigen Desktop Plattformen (Windows, macOS, Linux) stabil. In diesem Artikel möchte ich mich mit einem Thema beschäftigen, auf das die meisten Softwareentwickler bei UIs irgendwann stoßen: Applikationen in andere Sprachen übersetzen. Auch wenn man nicht den akuten Bedarf hat, so sollte man UIs möglichst von vorne herein darauf vorbereiten, dass sie übersetzbar sind. Übersetzung im Nachhinein einzubauen kann häufig sehr schwierig sein. Insbesondere, wenn Daten von außen bereits behaftet mit einer bestimmten Sprache in der eigenen Applikation ankommen.
Yaml Dateien mit C# parsen

Es gibt eine lange Liste von verbreiteten Markup-Formaten. Xml und Json sind dabei den allermeisten Entwicklern ein Begriff. Auch Yaml ist ein Format, welches nicht zuletzt durch den Einsatz bei Kubernetes oder anderen bekannten Applikationen eine größere Verbreitung genießt. Yaml wirkt auf den ersten Blick wie ein „Json ohne Klammern“. Das habe ich selbst tatsächlich auch lange so angenommen. Beschäftigt man sich etwas tiefer im Detail mit Yaml, so wird man aber schnell eines Besseren belehrt. Yaml bietet mehrere Features und hat etwa bei der Ermittlung der Datentypen ein mehr oder weniger komplexes Regelwerk. Aber warum überhaupt Yaml, wenn man doch auch Json einsetzen könnte? Yaml-Dateien könnten leichter durch einen Menschen geschrieben und gelesen werden. Aus diesem Grund wird es gerne für Konfigurationsdateien verwendet – so wie etwa bei Kubernetes. Somit kann es auch für C# Entwickler sinnvoll sein, anstelle von Json oder Xml eben Yaml für Konfigurationsdateien zu verwenden. Aus diesem Grund möchte ich mich in diesem Artikel mit dem Parsen von Yaml Dateien mit C# beschäftigen.
Typisierten HttpClient mit NSwag generieren
Fremde WEB-APIs anzusprechen ist längst eine Standardaufgabe für viele C# / .Net Entwickler. Einige folgen streng den Prinzipien von REST, andere wiederum nur grob. Als Gemeinsamkeit haben sie, dass die API über eine Swagger-Datei dokumentiert wird. Swagger-Dateien beschreiben alle zur Verfügung stehenden Endpunkte zusammen mit den Datenobjekten, welche zum Dienst und zurück zum Client übertragen werden. Daneben gibt es noch weitere Informationen, etwa zu möglichen Fehlern oder zu Gültigkeitsbereichen einzelner Felder. In den letzten Jahren habe ich mehrere Projekte gesehen, welche die Swagger-Dokumentation als Basis für einen eigenen, typisierten HttpClient verwenden. Der typisierte HttpClient wurde dabei aber meist von Hand programmiert. Das muss nicht immer so sein. Mit NSwag [1] etwa steht ein Werkzeug zur Verfügung, mit dessen Hilfe ein typisierter HttpClient generiert werden kann. In diesem Artikel möchte ich das anhand einer ASP.Net Core Blazor Applikation zeigen.
Texture sampling in SeeingSharp 2
In den letzten Tagen hatte ich wieder Zeit, an der 3D-Engine SeeingSharp 2 weiterzuarbeiten. Diesmal ging es darum, allgemein das Arbeiten mit Texturen zu verbessern. Genauer geht es um das Texture sampling. Texture sampling bezeichnet den Prozess, wie Farbinformationen aus Texturen gelesen werden. Direct3D bietet hierbei eine lange Liste von Einstellungen. So kann etwa beeinflusst werden, nach welcher Logik Texturen auf einer Fläche gekachelt werden sollen. Auch die Art, wie die Farben zweier benachbarter Pixel auf einer Textur vermischt werden, kann konfiguriert werden. Letzteres ist dann relevant, wenn eine Textur am Monitor mehr oder weniger Pixel beansprucht, als in der Textur selbst zur Verfügung stehen. Insgesamt hat SeeingSharp 2 bis jetzt nur ein Standard-Set an Einstellungen mit Anisotroper Filterung [1] unterstützt. Passt dieses Standard-Set nicht, so hatte man bis dato keine Möglichkeit, das Texture sampling zu beeinflussen.
Das DataGrid von Avalonia
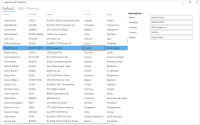
Das auf .Net basierende Cross-Plattform UI Framework Avalonia verfügt über eine große Palette an Standard-Controls. Es ist vieles dabei, was man als Entwickler typischerweise braucht. So gibt es etwa diverse Eingabeboxen, Controls für Auflistungen und welche, über die das Layout beeinflusst werden kann. Wenn ich auf Business-Applikationen schaue, fällt mir zudem noch ein sehr wichtiges ein, welches Avalonia mitbringt: Das DataGrid. Die Aufgabe eines DataGrids besteht grundsätzlich darin, eine mehr oder weniger lange Liste von Objekten in tabellarischer Form darzustellen. Jede Zeile ist ein solches Objekt, jede Spalte bezieht sich auf eine Eigenschaft. Daneben gibt es typischerweise Anforderungen wie zum Beispiel Sortierung, Filterung oder Gruppierung. Das DataGrid in Avalonia liefert diese Features entweder direkt oder bringt sie über den kleinen Umweg einer CollectionView im ViewModel mit. In diesem Artikel möchte ich mich mit den Features beschäftigen, welche das DataGrid in Avalonia im Standard mitbringt und wie man diese verwendet.
Hexagonale Architektur mit C#, .NET 6 und Blazor
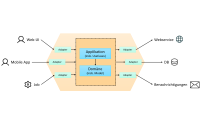
Zur Strukturierung von Software existiert eine Vielzahl von Architekturmustern. Unter dem Begriff Clean Architecture lassen sich mehrere davon zusammenfassen, welche sich zwar im Detail unterscheiden, beim Ziel allerdings auf das gleiche setzen: Trennung von Verantwortlichkeiten. Im Ideal wird dadurch eine Software erreicht, die sich langfristig einfach warten und erweitern lässt. In diesem Artikel möchte ich neben den allgemeinen Prinzipien der Clean Architecture ebenso anhand des Architekturmusters „Hexagonale Architektur“ ins Detail gehen. Über ein Praxisbeispiel werden wir einige Vor- und Nachteile dieser Vorgehensweise sehen. Das Beispiel verwendet C# / ASP.NET Core im Backend und APS.NET Core Blazor Webassembly im Frontend.
Prozesse kontrolliert stoppen mit C#

C# bzw. .Net bieten von Haus aus ein Set an Methoden und Klassen, um mit anderen Prozessen zu interagieren. So ermöglicht beispielsweise die Klasse System.Diagnostics.Process das Starten und Überwachen von fremden Prozessen. Auch die Konsolenausgabe kann ebenso mit wenigen Handgriffen abgegriffen werden. Wenn es allerdings um das Stoppen eines Prozesses geht, stehen lediglich die Methoden Kill und CloseMainWindow zur Verfügung. Erstere ist sehr unsauber, sie schießt den Prozess direkt ab. Der betroffene Prozess hat somit keine Möglichkeit mehr, sich kontrolliert herunterzufahren. Letztere funktioniert nur für Applikationen mit einer Benutzeroberfläche und (vermutlich) auch nur für Windows. In diesem Artikel möchte ich Wege zeigen, um Prozesse kontrolliert stoppen zu können. Hierbei wird lediglich zwischen dem darunter liegenden Betriebssystem (Windows, Linux oder macOS) unterschieden.
RingBuffer in C#
In .Net existiert eine Vielzahl von Klassen zur Auflistung von Objekten oder Strukturen. Ein einfaches und häufig verwendetes Beispiel ist die Array. Die List<T> ist ebenso stark verbreitet. Daneben gibt es eine Vielzahl von Klassen, welche diverse Spezialfälle abbilden. So etwa für parallelen Zugriff mit den Klassen aus dem Namespace System.Collections.Concurrent. Einen Spezialfall hätte ich allerdings schon häufiger vermisst: Den RingBuffer (oder auch Circular Buffer [1]). Ein RingBuffer dient dazu, eine fortlaufende Liste mit einer maximalen Länge abzubilden. Wenn über die maximale Länge hinaus geschrieben wird, so werden einfach die ältesten Elemente überschrieben. Gehen wir von der max. Länge von 100 aus. Wenn das 101. Element hinzugefügt wird, fliegt das erste Element raus. Dieses neue Element ist dann aber nicht der neue Start der Liste. Der Start der Liste ist immer das älteste Element. Wo benötigt man so ein Verhalten? Ein gutes Beispiel dazu habe ich in der 3D-Engine SeeingSharp. Zur Berechnung der durchschnittlichen FPS (Frames per Second bzw. Bilder pro Sekunde) wird der aktuelle FPS Wert je Sekunde berechnet und an einer Liste angehängt. Nachdem diese Liste eine bestimmte Länge erreicht hat, wird mit jedem neuen Wert der älteste Eintrag entfernt. Die durchschnittlichen FPS ergeben sich anschließend mittels des Durchschnittswerts aller Elemente in der Liste. Mit einer List<T> könnte man dieses Verhalten per Add und RemoveAt(0) relativ einfach abbilden, bei einem RingBuffer dagegen steckt dieses Verhalten bereits im Add. Dazu gibt es beim RingBuffer noch weitere Vorteile aus Sicht der Performance, doch dazu im Verlauf dieses Artikels mehr.
Testautomatisierung beim Parsing von Dokumenten

Als Entwickler steht man regelmäßig vor der Aufgabe, Dokumente mit einem bestimmten Format zu lesen und weiterzuverarbeiten. Ebenso kommt es immer wieder vor, dass es für das gewünschte Dokumentenformat noch keinen passenden Parser gibt. Daraus entsteht die Aufgabe, selbst einen kleinen Parser zu entwickeln. Gesagt, getan. Bei Xml- oder Json-Dokumenten etwa ist das i. d. R. auch relativ schnell erledigt. Nicht selten gibt es aber dennoch verschiedene Besonderheiten, die es zu beachten gilt. Etwa bestimmte Elemente in der Datei, die nicht immer enthalten sind. Nehmen wir als Beispiel ein Dokument, welches einen Kassenbon abbildet. Standardmäßig stehen alle Artikel drin, welche der Kunde gekauft hat. Es gibt allerdings weitere Fälle, wie Artikelrückgaben (Pfand), Stornierung einzelner Zeilen durch das Kassenpersonal, rabattierte Artikel etc. Schnell ergibt sich eine längere Liste von Fällen, die das Parsing und die anschließende Weiterverarbeitung beeinflussen. Aus diesem Grund kann es eine gute Idee sein, möglichst viele Teile davon per Testautomatisierung abzusichern.